#
talkinghead
#
它是什么?
AITuber的Talking Head Anime 3 Demo的实现。它具有以下功能:
- 从单个静态图像生成随机的类似Live 2D的运动动作。
- 与任何TTS输出的声音同步发音。
此扩展包含来自“Talking Head(?) Anime from a Single Image 3: Now the Body Too”项目的原始演示程序。顾名思义,该项目允许您为动漫角色动画,而您只需要该角色的单个图像即可。共有两个演示程序:
manual_poser允许您通过图形用户界面操控角色的面部表情、头部旋转、身体旋转和因呼吸而导致的胸部扩张,因此您可以将其保存为默认表情,例如快乐、悲伤、喜悦等。 ifacialmocap_puppeteer允许您将面部动作转移到动漫角色上。
#
硬件要求
您可以使用 CPU 或 GPU 模式(CPU 为默认模式)。但是,在 CPU 模式下,预计约为 1 FPS,而在 GPU 模式下,使用 RTX3060 我获得约 9-10 FPS。
ifacialmocap_puppeteer 需要一台能够从视频源计算混合形状参数的 iOS 设备。这意味着该设备必须能够运行 iOS 11.0 或更高版本,并且必须具备 TrueDepth 前置摄像头。(有关更多信息,请参见此页面。)换句话说,如果您拥有 iPhone X 或更好的设备,您应该没问题。
#
如何使用
您必须启动 extras 模块以使 talkinghead 正常工作:classify 和 talkinghead!
classify 是处理 talkinghead.png 文件所必需的。此外,您还可以使用 --talkinghead-gpu 将混合模型加载到 GPU 内存中,使动画速度提高 10 倍。强烈建议使用 GPU 加速!默认情况下,程序启动后将加载默认图像 SillyTavern-extras\talkinghead\tha3\images\lambda_00.png。您可以通过访问 http://localhost:5100/api/talkinghead/result_feed 或 YOUR EXT URL:PORT/api/talkinghead/result_feed 来验证它是否正常工作。
服务器启动后,转到扩展 API 选项卡并连接。然后只需选择一个角色卡以加载。(
--enable-modules=classify,talkinghead --talkinghead-gpu启动 server.py 时)现在选择角色表情,如果您勾选图像类型 talkinghead 框,脚本将用
YOUR EXT URL:PORT/api/talkinghead/result_feed的结果替换当前角色表情,取消勾选该框应该将图像返回到原始表情,但有时您需要发送新消息以“重新加载”图像。如果角色目录中没有 talkinghead.png 文件,它将简单地显示默认图像或最后一个具有 talkinghead.png 文件的角色卡。当角色卡更改时,动画源图像也会更改。
现在打开角色表情,向下滚动到 talkinghead 图像并上传符合下面“输入图像约束”部分要求的图像文件。
然后勾选和取消勾选 talkinghead 框以重新加载角色。如果图像看起来很滑稽,可能是因为它不透明/没有 alpha 通道。否则,请按照下面的说明和模板操作。
#
输入图像的约束
为了使系统正常工作,输入图像必须遵循以下约束:
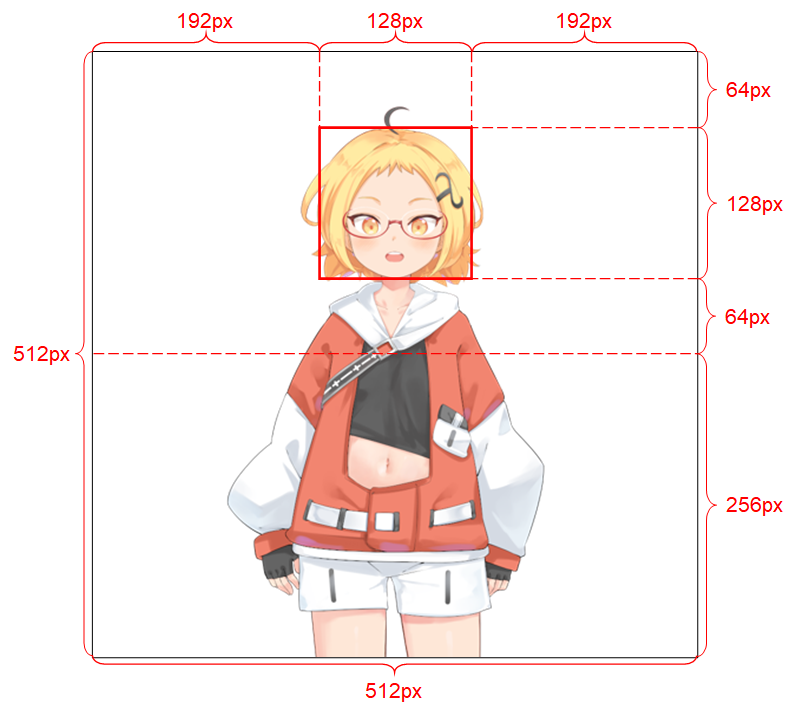
它的分辨率应为 512 x 512。 (如果程序接收到其他大小的输入图像,它将把图像调整为此分辨率并且也以此分辨率输出。) 它必须具有 alpha 通道。 它必须只包含一个类人角色。 角色应直立并面向前方。 角色的手应位于头部下方且远离头部。 角色的头部应大致包含在图像上半部分中间的 128 x 128 框内。 所有不属于角色的像素的 alpha 通道(即背景像素)必须为 0。
#
高级部分
#
Python 环境
除了基础功能 (app.py) 之外,manual_poser 和 ifacialmocap_puppeteer 还可以作为桌面应用程序使用。要运行它们,您需要为运行用 Python 语言编写的程序设置一个环境。该环境需要包含以下软件包:
- Python >= 3.8
- PyTorch >= 1.11.0,支持 CUDA
- SciPY >= 1.7.3
- wxPython >= 4.1.1
- Matplotlib >= 3.5.1
一种方法是安装 Anaconda 并在您的 shell 中运行以下命令:
conda create -n talking-head-anime-3-demo python=3.8
conda activate talking-head-anime-3-demo
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
conda install scipy
pip install wxpython
conda install matplotlib
#
额外的混合模型
只包含一个(最轻)模型,如果您想要额外的混合模型,您需要从 https://www.dropbox.com/s/y7b8jl4n2euv8xe/talking-head-anime-3-models.zip?dl=0 下载模型文件,并将其解压到 SillyTavern-extras\talkinghead\tha3\models 文件夹中。最终,数据文件夹应如下所示:
- tha3
- models
- separable_float
- editor.pt
- eyebrow_decomposer.pt
- eyebrow_morphing_combiner.pt
- face_morpher.pt
- two_algo_face_body_rotator.pt
- separable_half
- editor.pt :
- two_algo_face_body_rotator.pt
- standard_float
- editor.pt :
- two_algo_face_body_rotator.pt
- standard_half
- editor.pt :
- two_algo_face_body_rotator.pt
- separable_float
- models
模型文件根据创意共享署名 4.0 国际许可证进行分发,这意味着您可以将其用于商业目的。然而,Pramook Khungurn. Talking Head(?) Anime from a Single Image 3: Now the Body Too. https://github.com/pkhungurn/talking-head-anime-3-demo 是创作者。
#
运行 manual_poser 桌面应用程序
打开一个终端。将您的工作目录更改为仓库的根目录。然后,运行:
python tha3/app/manual_poser.py 请注意,在运行上述命令之前,您可能需要激活包含所需软件包的 Python 环境。
conda activate extras 如果您尚未激活该环境。